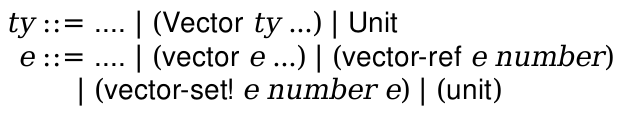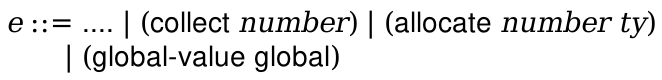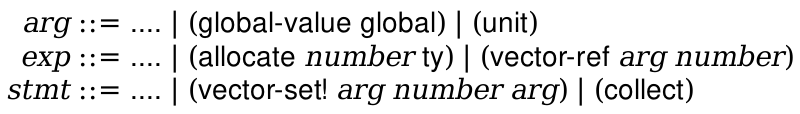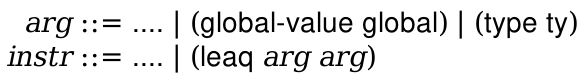2021 Spring - 406 - Compiler Construction - Syllabus
1 Important Course Details
This course provides the following Essential Learning Outcomes (ELOs):
Information Literacy (IL): The ability to use digital technologies, communication tools and/or networks to define a problem or an information need; devise an effective search strategy;identify, locate, and evaluate appropriate sources; and manage, synthesize, use and effectively communicate information ethically and legally.
2 Schedule
Day |
| Date |
| Topic |
| Notes | ||
1 |
| Tue |
| 01/26 |
| Preliminaries |
|
|
2 |
| Thu |
| 01/28 |
| Integers and Variables |
|
|
3 |
| Tue |
| 02/02 |
| Integers and Variables |
|
|
4 |
| Thu |
| 02/04 |
| Integers and Variables |
|
|
5 |
| Tue |
| 02/09 |
| Register Allocation |
|
|
6 |
| Thu |
| 02/11 |
| Register Allocation |
|
|
| Tue |
| 02/16 |
| No class | |||
7 |
| Thu |
| 02/18 |
| Register Allocation |
|
|
8 |
| Tue |
| 02/23 |
| Control Flow |
|
|
9 |
| Thu |
| 02/25 |
| Control Flow |
|
|
10 |
| Tue |
| 03/02 |
| Control Flow |
|
|
11 |
| Thu |
| 03/04 |
| Heap Allocation and GC |
|
|
12 |
| Tue |
| 03/09 |
| Heap Allocation and GC |
|
|
13 |
| Thu |
| 03/11 |
| Heap Allocation and GC |
|
|
14 |
| Tue |
| 03/16 |
| Functions |
|
|
15 |
| Thu |
| 03/18 |
| Functions |
|
|
16 |
| Tue |
| 03/23 |
| Closures |
|
|
17 |
| Thu |
| 03/25 |
| Closures |
|
|
18 |
| Tue |
| 03/30 |
| Control-Flow Analysis |
|
|
19 |
| Thu |
| 04/01 |
| Control-Flow Analysis |
| |
20 |
| Tue |
| 04/06 |
| Control-Flow Analysis |
| |
21 |
| Thu |
| 04/08 |
| Macro Expansion |
|
|
22 |
| Tue |
| 04/13 |
| Macro Expansion |
|
|
23 |
| Thu |
| 04/15 |
| Macro Expansion |
|
|
24 |
| Tue |
| 04/20 |
| Compilation Tools |
|
|
25 |
| Thu |
| 04/22 |
| Compilation Tools |
|
|
26 |
| Tue |
| 04/27 |
| Compilation Tools |
|
|
27 |
| Thu |
| 04/29 |
| Compilation Tools |
|
|
3 Work in this Course
3.1 Course Grade
3.2 Exam
3.3 Checkpoint
3.4 Course Project
Your main project in this course is to build a compiler for a high-level language to X86-64 assembly code. The lectures (and textbook) will walk through a particular design for this compiler that you will be expected to implement. There is a lot of flexibility about how you do this; in particular, you can implement it in whatever language you want. However, we mandate the source and target languages, as well as the overall design.
The textbook contains many code excerpts that are meant to be illustrative of how you could program the compiler. Do not copy them. You should do your own work. In addition, you should use the language you want to use, not necessarily Racket. Furthermore, the code excerpts in the book are not complete and need a large amount of massaging to function properly, even if you use Racket.
|
| Time |
| Lines | ||
1 |
| Define data types for R0 program ASTs. |
| 2m (0.07%) (1h) |
| +10 / -0 (0.20%) (10) |
2 |
| Write a pretty-printer for R0 programs. |
| 2m (0.07%) (1h) |
| +20 / -5 (0.49%) (25) |
3 |
| Build a test suite of a dozen R0 programs. |
| 4m (0.14%) (1h) |
| +22 / -1 (0.90%) (46) |
4 |
| Write an interpreter for R0 programs. |
| 3m (0.11%) (1h) |
| +16 / -1 (1.20%) (61) |
5 |
| Write a function that generates an R0 program that computes 2^N for a given N. |
| 2m (0.07%) (1h) |
| +16 / -3 (1.45%) (74) |
6 |
| Write a function that generates a random R0 program of depth N. |
| 4m (0.14%) (1h) |
| +34 / -6 (2.01%) (102) |
7 |
| Extend your test suite to generate a large number of random programs. |
| 0m (0.00%) (1h) |
| +3 / -1 (2.04%) (104) |
8 |
| Write some optimizer tests. |
| 6m (0.21%) (1h) |
| +38 / -18 (2.44%) (124) |
9 |
| Write an optimizer for R0. |
| 6m (0.21%) (1h) |
| +27 / -1 (2.95%) (150) |
10 |
| Extend your test suite to use your optimizer. |
| 6m (0.21%) (1h) |
| +22 / -8 (3.22%) (164) |
11 |
| Extend your data types from R0 to R1. |
| 1m (0.04%) (1h) |
| +6 / -1 (3.32%) (169) |
12 |
| Extend your pretty printer from R0 to R1. |
| 2m (0.07%) (1h) |
| +5 / -2 (3.38%) (172) |
13 |
| Write a dozen test R1 programs. |
| 4m (0.14%) (1h) |
| +28 / -4 (3.85%) (196) |
14 |
| Extend your interpreter from R0 to R1. |
| 1m (0.04%) (1h) |
| +12 / -6 (3.97%) (202) |
15 |
| Extend your random generation function from R0 to R1. |
| 3m (0.11%) (1h) |
| +19 / -9 (4.17%) (212) |
16 |
| Write some R1-specific optimizer tests. |
| 1m (0.04%) (1h) |
| +11 / -9 (4.21%) (214) |
17 |
| Extend your optimizer from R0 to R1. |
| 5m (0.18%) (1h) |
| +21 / -7 (4.48%) (228) |
18 |
| Define data types for X0 program ASTs. |
| 6m (0.21%) (1h) |
| +35 / -2 (5.13%) (261) |
19 |
| Write an emitter for X0 programs. |
| 11m (0.39%) (2h) |
| +54 / -12 (5.96%) (303) |
20 |
| Build a test suite of a dozen X0 programs. |
| 7m (0.25%) (2h) |
| +66 / -2 (7.21%) (367) |
21 |
| Write an interpreter for X0 programs. |
| 18m (0.64%) (2h) |
| +59 / -10 (8.18%) (416) |
22 |
| Connect your X0 test suite to your system assembler. |
| 15m (0.54%) (2h) |
| +105 / -51 (9.24%) (470) |
23 |
| Define data types for C0 program ASTs. |
| 2m (0.07%) (2h) |
| +19 / -3 (9.55%) (486) |
24 |
| Write a pretty printer for C0 programs. |
| 5m (0.18%) (2h) |
| +28 / -1 (10.08%) (513) |
25 |
| Build a test suite of a dozen C0 programs. |
| 9m (0.32%) (3h) |
| +52 / -1 (11.09%) (564) |
26 |
| Write an interpreter for C0 programs. |
| 7m (0.25%) (3h) |
| +33 / -6 (11.62%) (591) |
27 |
| Write a few tests for uniquify that predict its output. |
| 4m (0.14%) (3h) |
| +32 / -11 (12.03%) (612) |
28 |
| Implement the uniquify pass for R1 programs. |
| 4m (0.14%) (3h) |
| +26 / -1 (12.52%) (637) |
29 |
| Connect uniquify to your test suite. |
| 5m (0.18%) (3h) |
| +9 / -3 (12.64%) (643) |
30 |
| Write a half-dozen tests for resolve-complex that predict its output. |
| 6m (0.21%) (3h) |
| +30 / -10 (13.03%) (663) |
31 |
| Implement the resolve-complex pass for R1 programs. |
| 16m (0.57%) (3h) |
| +33 / -1 (13.66%) (695) |
32 |
| Connect resolve-complex to your test suite. |
| 38m (1.36%) (4h) |
| +74 / -31 (14.51%) (738) |
33 |
| Write a half-dozen tests for explicate-control that predict its output. |
| 13m (0.46%) (4h) |
| +84 / -27 (15.63%) (795) |
34 |
| Implement the explicate-control pass for R1 programs. |
| 4m (0.14%) (4h) |
| +22 / -1 (16.04%) (816) |
35 |
| Connect explicate-control to your test suite. |
| 3m (0.11%) (4h) |
| +9 / -3 (16.16%) (822) |
36 |
| Write a few tests for uncover-locals that predict its output. |
| 4m (0.14%) (4h) |
| +39 / -19 (16.55%) (842) |
37 |
| Implement the uncover-locals pass for C0 programs. |
| 4m (0.14%) (4h) |
| +18 / -1 (16.89%) (859) |
38 |
| Connect uncover-locals to your test suite. |
| 6m (0.21%) (4h) |
| +85 / -76 (17.06%) (868) |
39 |
| Write a half-dozen tests for select-instr that predict its output. |
| 7m (0.25%) (5h) |
| +40 / -8 (17.69%) (900) |
40 |
| Implement the select-instr pass for C0 programs. |
| 6m (0.21%) (5h) |
| +32 / -1 (18.30%) (931) |
41 |
| Connect select-instr to your test suite. |
| 9m (0.32%) (5h) |
| +32 / -20 (18.54%) (943) |
42 |
| Write a few tests for assign-homes that predict its output. |
| 8m (0.29%) (5h) |
| +41 / -5 (19.25%) (979) |
43 |
| Implement the assign-homes pass for X0 programs. |
| 7m (0.25%) (5h) |
| +34 / -1 (19.89%) (1012) |
44 |
| Connect assign-homes to your test suite. |
| 14m (0.50%) (5h) |
| +77 / -53 (20.37%) (1036) |
45 |
| Write a half-dozen tests for patch-instructions that predict its output. |
| 2m (0.07%) (5h) |
| +20 / -5 (20.66%) (1051) |
46 |
| Implement the patch-instructions pass for X0 programs. |
| 4m (0.14%) (5h) |
| +26 / -1 (21.15%) (1076) |
47 |
| Connect patch-instructions to your test suite. |
| 2m (0.07%) (5h) |
| +8 / -2 (21.27%) (1082) |
48 |
| Implement your language runtime. |
| 2m (0.07%) (5h) |
| +17 / -3 (21.55%) (1096) |
49 |
| Implement the main-generation pass for X0 programs. |
| 13m (0.46%) (6h) |
| +37 / -13 (22.02%) (1120) |
50 |
| Connect your test suite to your system assembler and language runtime. |
| 47m (1.68%) (6h) |
| +268 / -206 (23.24%) (1182) |
51 |
| Write a dozen tests for uncover-live that predict its output. |
| 10m (0.36%) (7h) |
| +65 / -7 (24.38%) (1240) |
52 |
| Implement the uncover-live pass for X0 programs. |
| 21m (0.75%) (7h) |
| +77 / -16 (25.57%) (1301) |
53 |
| Write a dozen tests for build-interferences that predict its output. |
| 7m (0.25%) (7h) |
| +28 / -3 (26.07%) (1326) |
54 |
| Implement the build-interferences pass for X0 programs. |
| 17m (0.61%) (7h) |
| +53 / -3 (27.05%) (1376) |
55 |
| Write a dozen tests for color-graph that predict its output. |
| 1m (0.04%) (7h) |
| +1 / -1 (27.05%) (1376) |
56 |
| Implement the color-graph function on arbitrary graphs. |
| 28m (1.00%) (8h) |
| +45 / -4 (27.86%) (1417) |
57 |
| Replace assign-homes with a new pass named assign-registers and implement the stupid-allocate-registers pass for X0 programs. |
| 1m (0.04%) (8h) |
| +3 / -4 (27.84%) (1416) |
58 |
| Write a dozen tests for the assign-registers that predict its output and check their behavior. |
| 1m (0.04%) (8h) |
| +4 / -2 (27.87%) (1418) |
59 |
| Write a dozen tests for allocate-registers that predict its output. |
| 7m (0.25%) (8h) |
| +23 / -23 (27.87%) (1418) |
60 |
| Replace stupid-allocate-registers with a new allocate-registers pass on X0 programs. |
| 20m (0.71%) (8h) |
| +47 / -18 (28.45%) (1447) |
61 |
| Update the main-generation pass to save and restore callee-saved registers. |
| 23m (0.82%) (9h) |
| +70 / -50 (28.84%) (1467) |
62 |
| Connect your test suite to the new main-generation and allocate-registers passes. |
| 14m (0.50%) (9h) |
| +19 / -14 (28.94%) (1472) |
63 |
| Write a few test programs that have opportunities for move-biasing to be effective. |
| 5m (0.18%) (9h) |
| +49 / -3 (29.84%) (1518) |
64 |
| Extend your build-interferences pass to construct a move-graph. |
| 7m (0.25%) (9h) |
| +28 / -13 (30.14%) (1533) |
65 |
| Extend your color-graph function to incorporate move-biasing with an optional input argument. |
| 7m (0.25%) (9h) |
| +13 / -6 (30.27%) (1540) |
66 |
| Update your allocate-registers pass to make use of the move-biasing feature of color-graph. |
| 9m (0.32%) (9h) |
| +36 / -32 (30.35%) (1544) |
67 |
| Extend your data types from R1 to R2. |
| 5m (0.18%) (10h) |
| +19 / -1 (30.71%) (1562) |
68 |
| Extend your pretty printer from R1 to R2. |
| 1m (0.04%) (10h) |
| +6 / -2 (30.78%) (1566) |
69 |
| Write a dozen test R2 programs. |
| 5m (0.18%) (10h) |
| +43 / -1 (31.61%) (1608) |
70 |
| Extend your interpreter from R1 to R2. |
| 2m (0.07%) (10h) |
| +7 / -2 (31.71%) (1613) |
71 |
| Write type-checker tests for R2. |
| 5m (0.18%) (10h) |
| +60 / -41 (32.08%) (1632) |
72 |
| Write a type-checker for R2. |
| 18m (0.64%) (10h) |
| +124 / -75 (33.05%) (1681) |
73 |
| Extend your random generation function from R1 to R2. |
| 18m (0.64%) (10h) |
| +34 / -14 (33.44%) (1701) |
74 |
| Write some R2-specific optimizer tests. |
| 7m (0.25%) (10h) |
| +27 / -6 (33.85%) (1722) |
75 |
| Extend your optimizer from R1 to R2. |
| 10m (0.36%) (11h) |
| +51 / -30 (34.26%) (1743) |
76 |
| Extend the uniquify pass from R1 to R2 programs, with a few test cases to check its output. |
| 1m (0.04%) (11h) |
| +9 / -4 (34.36%) (1748) |
77 |
| Extend your data types from C0 to C1. |
| 2m (0.07%) (11h) |
| +6 / -1 (34.46%) (1753) |
78 |
| Extend your pretty-printer from C0 to C1 programs. |
| 3m (0.11%) (11h) |
| +9 / -2 (34.60%) (1760) |
79 |
| Write a half-dozen C1 test programs. |
| 6m (0.21%) (11h) |
| +51 / -3 (35.54%) (1808) |
80 |
| Extend your interpreter from C0 to C1 programs. |
| 3m (0.11%) (11h) |
| +14 / -7 (35.68%) (1815) |
81 |
| Extend your data types from X0 to X1. |
| 2m (0.07%) (11h) |
| +10 / -2 (35.84%) (1823) |
82 |
| Extend your emitter from X0 to X1 programs. |
| 6m (0.21%) (11h) |
| +10 / -2 (35.99%) (1831) |
83 |
| Write a half-dozen X1 test programs. |
| 11m (0.39%) (11h) |
| +38 / -3 (36.68%) (1866) |
84 |
| Extend your interpreter from X0 to X1 programs. |
| 13m (0.46%) (11h) |
| +38 / -16 (37.11%) (1888) |
85 |
| Extend the resolve-complex pass from R1 to R2 programs, with a few test cases to check its output. |
| 72m (2.57%) (13h) |
| +180 / -78 (39.12%) (1990) |
86 |
| Extend the explicate-control pass from R1 to R2 programs, with a half-dozen tests that predict its output. |
| 44m (1.57%) (13h) |
| +84 / -11 (40.55%) (2063) |
87 |
| Extend the uncover-locals pass for C1 programs. |
| 1m (0.04%) (13h) |
| +9 / -4 (40.65%) (2068) |
88 |
| Extend the select-instr pass for C1 programs, with a few test cases to check its output. |
| 28m (1.00%) (14h) |
| +75 / -15 (41.83%) (2128) |
89 |
| Write a half-dozen tests for the uncover-live pass. |
| 4m (0.14%) (14h) |
| +1 / -1 (41.83%) (2128) |
90 |
| Extend your uncover-live pass for X1 programs. |
| 37m (1.32%) (15h) |
| +94 / -23 (43.23%) (2199) |
91 |
| Extend your build-interference pass for X1 programs, with a few test cases to check its output. |
| 4m (0.14%) (15h) |
| +18 / -16 (43.27%) (2201) |
92 |
| Extend the patch-instructions pass for X1 programs, with a few test cases to check its output. |
| 29m (1.04%) (15h) |
| +58 / -5 (44.31%) (2254) |
93 |
| Update your runtime to support printing out booleans, in addition to integers. |
| 1m (0.04%) (15h) |
| +6 / -1 (44.41%) (2259) |
94 |
| Update your main-generation pass for boolean-outputting programs. |
| 11m (0.39%) (15h) |
| +63 / -49 (44.68%) (2273) |
95 |
| Extend your compiler to support conditional moves. |
| 66m (2.36%) (16h) |
| +88 / -51 (45.41%) (2310) |
96 |
| Extend your data types from R2 to R3. |
| 2m (0.07%) (16h) |
| +11 / -3 (45.57%) (2318) |
97 |
| Extend your pretty printer from R2 to R3. |
| 4m (0.14%) (16h) |
| +12 / -2 (45.76%) (2328) |
98 |
| Write a dozen test R3 programs. |
| 5m (0.18%) (17h) |
| +28 / -1 (46.29%) (2355) |
99 |
| Extend your interpreter from R2 to R3. |
| 1m (0.04%) (17h) |
| +10 / -4 (46.41%) (2361) |
100 |
| Write type-checker tests for R3. |
| 4m (0.14%) (17h) |
| +19 / -1 (46.77%) (2379) |
101 |
| Extend your type-checker from R2 to R3. |
| 6m (0.21%) (17h) |
| +26 / -11 (47.06%) (2394) |
102 |
| Extend your random generation function from R2 to R3. |
| 9m (0.32%) (17h) |
| +28 / -5 (47.51%) (2417) |
103 |
| Write a function that generates an R3 program that uses N bytes of memory and makes it unreachable M times. |
| 33m (1.18%) (17h) |
| +40 / -2 (48.26%) (2455) |
104 |
| Write some R3-specific optimizer tests. |
| 2m (0.07%) (17h) |
| +7 / -4 (48.32%) (2458) |
105 |
| Extend your optimizer from R2 to R3. |
| 21m (0.75%) (18h) |
| +70 / -17 (49.36%) (2511) |
106 |
| Modify your type-checker so that it wraps every expression in its type. |
| 52m (1.86%) (19h) |
| +130 / -37 (51.19%) (2604) |
107 |
| Extend the uniquify pass from R2 to R3 programs, with a few test cases to check its output. |
| 3m (0.11%) (19h) |
| +53 / -28 (51.68%) (2629) |
108 |
| Implement the expose-allocation pass on typed R3 programs. |
| 23m (0.82%) (19h) |
| +111 / -8 (53.71%) (2732) |
109 |
| Extend your R3 interpreter to handle these new forms. |
| 16m (0.57%) (19h) |
| +24 / -21 (53.76%) (2735) |
110 |
| Extend the resolve-complex pass from R2 to R3 programs, with a few test cases to check its output. |
| 22m (0.79%) (20h) |
| +74 / -25 (54.73%) (2784) |
111 |
| Extend your data types from C1 to C2. |
| 4m (0.14%) (20h) |
| +15 / -3 (54.96%) (2796) |
112 |
| Extend your pretty-printer from C1 to C2 programs. |
| 4m (0.14%) (20h) |
| +15 / -5 (55.16%) (2806) |
113 |
| Write a half-dozen tests for C2. |
| 1m (0.04%) (20h) |
| +3 / -1 (55.20%) (2808) |
114 |
| Extend your interpreter from C1 to C2 programs. |
| 3m (0.11%) (20h) |
| +19 / -7 (55.44%) (2820) |
115 |
| Extend your explicate-control pass to target C2. |
| 14m (0.50%) (20h) |
| +36 / -13 (55.89%) (2843) |
116 |
| Extend your uncover-locals pass from C1 to C2. |
| 15m (0.54%) (20h) |
| +112 / -97 (56.18%) (2858) |
117 |
| Extend your data types from X1 to X2. |
| 1m (0.04%) (20h) |
| +4 / -1 (56.24%) (2861) |
118 |
| Extend your emitter from X1 to X2 programs. |
| 1m (0.04%) (20h) |
| +4 / -1 (56.30%) (2864) |
119 |
| Extend the select-instr pass to target X2. |
| 23m (0.82%) (21h) |
| +75 / -45 (56.89%) (2894) |
120 |
| Write a half-dozen X2 test programs. |
| 17m (0.61%) (21h) |
| +17 / -15 (56.93%) (2896) |
121 |
| Extend your interpreter from X1 to X2 programs. |
| 36m (1.29%) (22h) |
| +51 / -35 (57.24%) (2912) |
122 |
| Extend remaining passes for X2. |
| 61m (2.18%) (23h) |
| +127 / -88 (58.01%) (2951) |
123 |
| Update your runtime to support the allocation interface. |
| 88m (3.14%) (24h) |
| +387 / -232 (61.06%) (3106) |
124 |
| Update your runtime to support printing out vectors. |
| 63m (2.25%) (25h) |
| +43 / -13 (61.65%) (3136) |
125 |
| Update your runtime to actually do garbage collection. |
| 28m (1.00%) (26h) |
| +260 / -38 (66.01%) (3358) |
126 |
| Extend your data types from R3 to R4. |
| 15m (0.54%) (26h) |
| +262 / -248 (66.29%) (3372) |
127 |
| Extend your pretty printer from R3 to R4. |
| 7m (0.25%) (26h) |
| +24 / -5 (66.66%) (3391) |
128 |
| Write a dozen test R4 programs. |
| 11m (0.39%) (26h) |
| +62 / -1 (67.86%) (3452) |
129 |
| Extend your interpreter from R3 to R4. |
| 8m (0.29%) (26h) |
| +60 / -43 (68.19%) (3469) |
130 |
| Write type-checker tests for R4. |
| 3m (0.11%) (26h) |
| +26 / -1 (68.68%) (3494) |
131 |
| Extend your type-checker from R3 to R4. |
| 34m (1.21%) (27h) |
| +77 / -32 (69.57%) (3539) |
132 |
| Extend your random generation function from R3 to R4. |
| 58m (2.07%) (28h) |
| +157 / -76 (71.16%) (3620) |
133 |
| Write some R4-specific optimizer tests. |
| 1m (0.04%) (28h) |
| +7 / -3 (71.24%) (3624) |
134 |
| Extend your optimizer from R3 to R4. |
| 66m (2.36%) (29h) |
| +270 / -185 (72.91%) (3709) |
135 |
| Extend the uniquify pass from R3 to R4 programs, with a few test cases to check its output. |
| 6m (0.21%) (29h) |
| +31 / -10 (73.32%) (3730) |
136 |
| Implement the reveal-fun pass on R4 programs. |
| 3m (0.11%) (29h) |
| +15 / -7 (73.48%) (3738) |
137 |
| Implement the limit-fun pass on R4 programs. |
| 31m (1.11%) (30h) |
| +138 / -7 (76.06%) (3869) |
138 |
| Extend the resolve-complex pass to R4 programs. |
| 52m (1.86%) (31h) |
| +138 / -16 (78.45%) (3991) |
139 |
| Extend your data types from C2 to C3. |
| 7m (0.25%) (31h) |
| +12 / -10 (78.49%) (3993) |
140 |
| Extend your pretty-printer from C2 to C3 programs. |
| 15m (0.54%) (31h) |
| +251 / -213 (79.24%) (4031) |
141 |
| Write a half-dozen tests for C3. |
| 37m (1.32%) (32h) |
| +4 / -2 (79.28%) (4033) |
142 |
| Extend your interpreter from C2 to C3 programs. |
| 20m (0.71%) (32h) |
| +89 / -78 (79.50%) (4044) |
143 |
| Extend your explicate-control pass to target C3. |
| 29m (1.04%) (32h) |
| +72 / -41 (80.11%) (4075) |
144 |
| Extend your uncover-locals pass from C2 to C3. |
| 14m (0.50%) (33h) |
| +132 / -109 (80.56%) (4098) |
145 |
| Extend your data types from X2 to X3. |
| 8m (0.29%) (33h) |
| +13 / -6 (80.70%) (4105) |
146 |
| Extend your emitter from X2 to X3 programs. |
| 16m (0.57%) (33h) |
| +331 / -316 (80.99%) (4120) |
147 |
| Write a half-dozen X3 test programs. |
| 5m (0.18%) (33h) |
| +320 / -309 (81.21%) (4131) |
148 |
| Extend your interpreter from X2 to X3 programs. |
| 50m (1.79%) (34h) |
| +284 / -276 (81.36%) (4139) |
149 |
| Extend the select-instr pass to target X3. |
| 72m (2.57%) (35h) |
| +164 / -70 (83.21%) (4233) |
150 |
| Extend allocate-registers (and its helper passes) for X3. |
| 237m (8.46%) (39h) |
| +671 / -546 (85.67%) (4358) |
151 |
| Extend patch-instructions for X3. |
| 33m (1.18%) (40h) |
| +79 / -87 (85.51%) (4350) |
152 |
| Update your runtime to deal with printing references to functions and function types. |
| 102m (3.64%) (41h) |
| +187 / -98 (87.26%) (4439) |
153 |
| Extend your data types from R4 to R5. |
| 1m (0.04%) (41h) |
| +1 / -1 (87.26%) (4439) |
154 |
| Extend your pretty printer from R4 to R5. |
| 2m (0.07%) (41h) |
| +13 / -3 (87.46%) (4449) |
155 |
| Write a dozen test R5 programs. |
| 10m (0.36%) (42h) |
| +74 / -19 (88.54%) (4504) |
156 |
| Extend your interpreter from R4 to R5. |
| 3m (0.11%) (42h) |
| +15 / -3 (88.78%) (4516) |
157 |
| Write type-checker tests for R5. |
| 1m (0.04%) (42h) |
| +5 / -1 (88.85%) (4520) |
158 |
| Extend your type-checker from R4 to R5. |
| 6m (0.21%) (42h) |
| +23 / -4 (89.23%) (4539) |
159 |
| Extend your random generation function from R4 to R5. |
| 5m (0.18%) (42h) |
| +26 / -15 (89.44%) (4550) |
160 |
| Write some R5-specific optimizer tests. |
| 1m (0.04%) (42h) |
| +9 / -5 (89.52%) (4554) |
161 |
| Extend your optimizer from R4 to R5. |
| 28m (1.00%) (42h) |
| +33 / -7 (90.03%) (4580) |
162 |
| Extend the boring passes from R4 to R5 programs. |
| 5m (0.18%) (42h) |
| +18 / -7 (90.25%) (4591) |
163 |
| Implement the convert-to-closure pass on R5 programs. |
| 97m (3.46%) (44h) |
| +277 / -87 (93.98%) (4781) |
164 |
| Add a simple macro system based on syntax-rules to your compiler. |
| 61m (2.18%) (45h) |
| +116 / -24 (95.79%) (4873) |
165 |
| Use your macro system to replace some of the syntactic sugar in your compiler, like the and & or transformations. |
| 17m (0.61%) (45h) |
| +63 / -5 (96.93%) (4931) |
166 |
| Write a parser for your programs. |
| 66m (2.36%) (47h) |
| +157 / -39 (100.00%) (5087) |
167 |
| Expand R5 to have more features. |
| 43m (1.54%) (46h) |
| +68 / -30 (97.68%) (4969) |
168 |
| Implement k-CFA for R5 and incorporate it into your optimizer. |
|
| ||
169 |
| Connect your compiler to LLVM. |
|
|